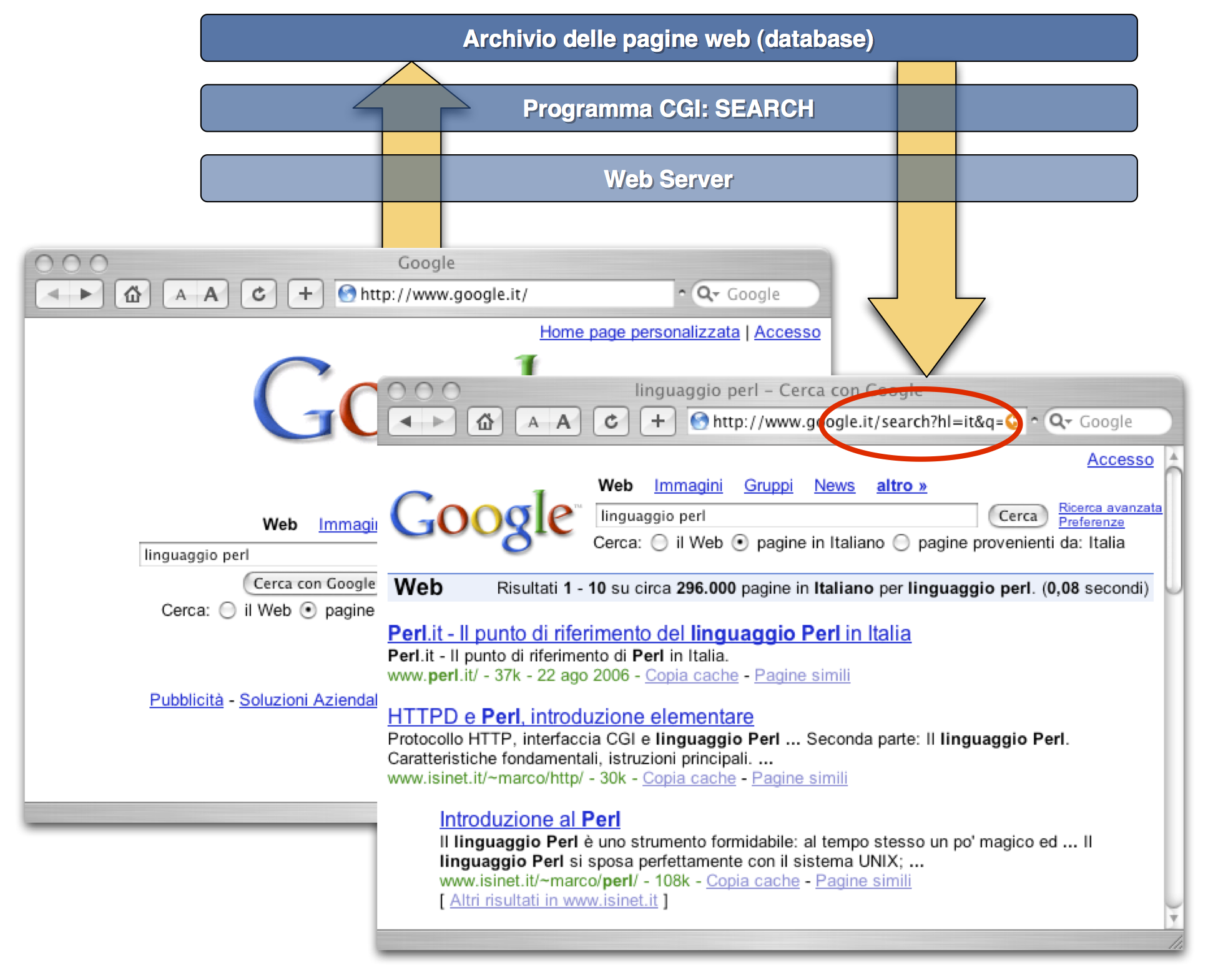
Il processo di chiamata del programma CGI e restituzione dell'output
In quest'ultimo capitolo sono riportati alcuni script che implementano degli esempi più significativi di quelli riportati nelle pagine precedenti per descrivere singole istruzioni del linguaggio. Questi script non sono puramente esemplificativi, ma affrontano e risolvono problemi di una qualche utilità e consentono di vedere “in azione” il linguaggio di scripting su casi di più ampio respiro.
Il primo esempio consiste in un tipico task di amministrazione di un sistema operativo UNIX/Linux, ossia la cosiddetta “rotazione” dei file di log di un'applicazione. Per semplificare le operazioni di archiviazione e di gestione dei file contenenti le informazioni di log sul funzionamento e sugli errori di un determinato servizio, spesso si fa in modo di conservare su file distinti i log relativi a giorni differenti: in questo modo ogni file conterrà solo le informazioni relative ad un periodo di tempo di 24 ore e dunque avrà una dimensione contenuta, che è possibile archiviare o gestire con maggiore facilità rispetto ad un unico file di log molto ingombrante. Siccome spesso i file di log sono utili per determinare qualche malfunzionamento o comportamento anomalo da parte delle applicazioni, è possibile che non sia opportuno conservare file di log molto vecchi, ma che sia sufficiente mantenere archiviati (magari in formato compresso) solo quelli relativi agli ultimi giorni.
L'operazione che consente di mantenere un archivio aggiornato solo con gli ultimi file di log, eliminando i precedenti, si chiama in gergo “rotazione dei file di log”. Ciascun file viene infatti identificato da un numero progressivo (da 0 ad n, dove n+1 è il numero di file di log che si intende conservare) nel nome del file stesso e, ad ogni intervallo di rotazione (ad esempio, pianificando l'esecuzione automatica di questa operazione ogni 24 ore, utilizzando utility come “crond”), ciascun file viene rinominato utilizzando il progressivo incrementato di 1; il file con il progressivo n viene eliminato, sovrapponendolo con il file che aveva il progressivo n−1. Il file di log corrente, infine, viene rinominato utilizzando il progressivo 0 e si crea un nuovo file di log completamente vuoto, privo di progressivo.
Ad esempio, se l'applicazione “myapp” produce un file di log in “/tmp/mylog”, allora applicare l'operazione di log rotation a quel file, significa spostare ogni volta il log “mylog” nel file “mylog.0” e creare un nuovo file vuoto denominato “mylog”. Per mantenere in archivio i file relativi alle ultime n turnazioni, prima di rinominare il log corrente si provvederà a rinominare/spostare “mylog.n−1” in “mylog.n”, “mylog.n−2” in “mylog.n−” e così via, fino a spostare “mylog.0” in “mylog.1”.
Lo script riportato di seguito esegue proprio questa operazione, avendo cura, in aggiunta, di comprimere i file di log archiviati (non quello corrente) in modo da risparmiare spazio sul filesystem.
1 #!/bin/bash
2 # logrotate.sh
3 # Rinomina tutti i log file presenti nella directory $LOGDIR
4 # il cui nome corrisponde con $LOGNAME; viene eliminato il file
5 # piu' vecchio (ultimo della coda), creando un nuovo file vuoto
6 # all'inizio della coda.
7 #
8 # Variabili di configurazione dello script
9 #
10 LOGDIR='/tmp'
11 LOGNAME='mylog'
12 LOGRETENTION=7
13 GZIP='/usr/bin/gzip'
14 #
15 # Verifiche sulla corretta accessibilita' della directory dei log
16 #
17 if [[ ! -d "$LOGDIR" ]] ; then
18 echo "$0: ERRORE: la directory $LOGDIR non esiste."
19 exit 1
20 fi
21 if [[ ! -w "$LOGDIR" ]] ; then
22 echo "$0: ERRORE: non e' possibile modificare il contenuto della \
23 directory $LOGDIR."
24 exit 1
25 fi
26 #
27 # Eliminazione del log piu' vecchio e spostamento dei log file
28 # piu' recenti
29 #
30 for (( i=LOGRETENTION ; i>0; i-- )); do
31 ((j=i-1))
32 if [[ -e $LOGDIR/$LOGNAME.$j.gz ]] ; then
33 if [[ -w $LOGDIR/$LOGNAME.$j.gz && \
34 (-w $LOGDIR/$LOGNAME.$i.gz || ! -e $LOGDIR/$LOGNAME.$i.gz) ]]
35 then
36 mv $LOGDIR/$LOGNAME.$j.gz $LOGDIR/$LOGNAME.$i.gz
37 else
38 echo "$0: ERRORE: non e' possibile ruotare \
39 $LOGDIR/$LOGNAME.$j.gz in $LOGDIR/$LOGNAME.$i.gz"
40 exit 1
41 fi
42 fi
43 done
44 #
45 # Spostamento e compressione del log piu' recente e creazione di un
46 # nuovo log file vuoto
47 #
48 mv $LOGDIR/$LOGNAME $LOGDIR/$LOGNAME.0
49 touch $LOGDIR/$LOGNAME
50 $GZIP $LOGDIR/$LOGNAME.0
Le istruzioni iniziali definiscono alcune variabili che serviranno in seguito a configurare il funzionamento dello script (righe 10--13): la variabile LOGDIR contiene il path della directory in cui sono contenuti i file di log (nell'esempio “/tmp”, spesso nella pratica invece potrebbe essere “/var/log”), la variabile LOGNAME contiene il nome del file di log (“mylog” nel nostro esempio), la variabile LOGRETENTION contiene invece il massimo valore numerico progressivo da attribuire ai file di log archiviati: nell'esempio il valore è 7 e quindi saranno conservati otto file di archivio, da “mylog.0” fino a “mylog.7”. La variabile “GZIP” contiene infine il path assoluto del comando esterno “gzip”, una utility di GNU che consente di comprimere efficientemente dei file sul filesystem della macchina.
Le variabili di configurazione sono denominate con caratteri maiuscoli proprio per evidenziarle rispetto ad altre variabili che saranno utilizzate nell'ambito dello script. Inoltre la definizione dei valori di queste variabili è raccolta nelle prime righe dello script, in modo da semplificare la modifica della configurazione da parte di coloro che vorranno utilizzarlo sul proprio sistema. Entrambi questi accorgimenti costituiscono delle “buone pratiche” che è bene rispettare nella programmazione degli shell script.
Con le condizioni alle righe 17 e 21 si verifica, rispettivamente, se esiste la directory il cui path è specificato in LOGDIR e se l'utente che sta eseguendo lo script ha il permesso di scrivere in tale directory. Nel caso in cui una delle due condizioni risulti falsa, viene visualizzato un messaggio di errore sul terminale dell'utente e viene interrotta l'esecuzione dello script con l'istruzione “exit”, restituendo un return code diverso da zero per indicare la conclusione con una condizione di errore. In entrambe le istruzioni “if” la condizione è delimitata dalle doppie parentesi quadre “[[...]]”, necessarie per poter utilizzare gli operatori “-d” e “-w” che eseguono verifiche sullo stato del filesystem.
Il ciclo “for” alle righe 30--43 fa variare il valore della variabile i da LOGRETENTION (7 nell'esempio) a 1, diminuendo di un'unità ad ogni iterazione il valore di i; alla variabile j viene assegnato il valore i−1. Se esiste il file “$LOGDIR/$LOGNAME.$j.gz” (es.: “/tmp/mylog.5.gz”) e se è possibile modificare con i permessi assegnati all'utente che esegue lo script il file “$LOGDIR/$LOGNAME.$i.gz” o se questo file non esiste (riga 34), viene spostato il file “$LOGNAME.$j.gz” sul file “$LOGNAME.$i.gz”; altrimenti lo script termina con un messaggio di errore.
Dopo aver “ruotato” tutti i file di log archiviati, con le istruzioni riportate alle righe 48--50 lo script archivia il file di log corrente con il progressivo 0 e lo comprime con il programma “gzip”. Viene anche ricreato un file di log corrente vuoto, utilizzando il comando esterno “touch”. Il programma “touch” crea un file vuoto, se il nome specificato sulla linea di comando identifica un file che non esiste, altrimenti, se il file esiste, vengono aggiornate la data e l'ora di ultima modifica; in particolare nello script precedente, il comando “touch” crea certamente un nuovo file vuoto, dal momento che a riga 48 con l'istruzione “mv” un file con lo stesso nome era stato rinominato con un nome differente.
In questa sezione vogliamo dimostrare l'utilizzo del linguaggio Bash per la realizzazione di una semplice utility per la gestione di un archivio di nomi, indirizzi e numeri di telefono. Vogliamo realizzare un programma che operi con una doppia modalità, batch ed interattiva, come spesso avviene per diversi programmi in ambiente UNIX/Linux: il programma deve accettare delle opzioni sulla linea di comando che gli indicano l'operazione da compiere in modalità batch; se non è presente alcuna opzione il programma opererà invece in modalità interattiva, presentando un menù di scelte sul terminale dell'utente.
Vogliamo implementare uno script che supporti le seguenti funzionalità principali:
Procederemo alla progettazione e alla realizzazione dello script in modo “incrementale”, implementando prima le singole funzioni come degli shell script autonomi, e successivamente assemblando tutte le funzionalità in un unico script più grande. In questo modo intendiamo anche suggerire un approccio pragmatico alla realizzazione di script modulari, in modo da arrivare progressivamente all'implementazione di script più complessi.
L'archivio degli indirizzi, come spesso accade per numerosi programmi ed utility in ambiente UNIX, è costituito da un file di testo ASCII, in cui ciascun record è memorizzato su una riga del file ed i campi del record sono distinti fra di loro attraverso un carattere separatore (nel nostro esempio è il carattere pipe “|”). Naturalmente in questo modo la struttura dell'archivio è rigidamente posizionale, ossia i campi devono rispettare sempre lo stesso ordine all'interno del record; nel nostro esempio la sequenza dei campi che costituiscono ciascun record è la seguente: nome, cognome, telefono ed e-mail. Un esempio di archivio è il seguente:
Marco|Liverani|06 123 456|m.liverani@aquilante.net
Enrico|Pili|329 876 432|epili@pippo.it
Natascia|Piroso|02 214 365|pinat@gmail.com
Marco|Pedicini| |m_pedicini@uniroma3.it
Carlo|Giuffrida|0462 987 654|carlo.giuffrida@pippo.it
Da notare che nel quarto record manca il numero telefonico, per cui nella posizione di quel campo c'è una stringa costituita da uno spazio.
La prima funzionalità che intendiamo implementare è quella con cui i campi di un nuovo record vengono aggiunti al file di archivio. Lo script “recordInsert.sh” che implementa questa funzionalità è riportato di seguito:
1 #!/bin/bash
2 # recordInsert.sh
3 # Riceve come argomento sulla linea di comando il nome, cognome,
4 # telefono e e-mail e li inserisce in un nuovo record della rubrica
5 RUBRICA=~/.rubrica
6 nome=$1
7 cognome=$2
8 telefono=$3
9 email=$4
10 echo "$nome|$cognome|$telefono|$email" >> $RUBRICA
11 echo "Inserito record n. $(wc -l $RUBRICA | cut -c 1-8)"
Lo script accetta quattro parametri sulla linea di comando, il cui significato, anche in questo caso, è posizionale: i quattro parametri saranno considerati rispettivamente come il il nome da inserire nella rubrica, il cognome, il telefono ed infine l'indirizzo di posta elettronica. Anche se lo script è molto breve, per migliorarne la leggibilità e la manutenibilità, a riga 5 è stata definita la variabile RUBRICA che contiene il nome del file di archivio (nell'esempio il file “.rubrica” nella home directory dell'utente, rappresentata dal simbolo “~”).
Dopo aver memorizzato i quattro parametri nelle variabili nome, cognome, telefono ed email, l'istruzione fondamentale, che permette di aggiornare la rubrica degli indirizzi è quella riportata a riga 10, in cui l'output del comando “echo” viene rediretto, in modalità append, sul file $RUBRICA. Con l'operatore di redirezione “>>” l'output di “echo” viene aggiunto su una nuova riga alla fine del file; se il file non esiste, questo viene creato, aggiungendo come prima ed unica riga del file quella prodotta dal comando “echo”.
L'istruzione a riga 11 consente di visualizzare un messaggio sul terminale dell'utente che indica il numero di record presenti nella rubrica dopo l'inserimento appena effettuato. Per effettuare questo calcolo viene utilizzato il comando “wc” (word count), che con l'opzione “-l” esegue il conteggio delle righe presenti nel file indicato sulla linea di comando.
L'output del comando “wc” è il seguente, che non si presta bene ad essere inserito nell'output prodotto dallo script:
$ wc -l ~/.rubrica
5 /home/marco/.rubrica
Viene infatti riportato, oltre al numero di righe presenti nel file, anche il nome del file stesso (“~/.rubrica” nell'esempio).
Per “pulire” l'output prodotto da “wc”, eliminando i caratteri non desiderati, si può utilizzare il comando “cut”, con cui è possibile selezionare solo alcuni dei caratteri prodotti su standard output da “wc”. In particolare nell'esempio precedente, con il comando “cut -c 1-8” si indica al comando di selezionare solo i caratteri dal primo all'ottavo, scartando tutto il resto. Collegando in pipeline i due comandi si ottiene il seguente risultato:
$ wc -l ~/.rubrica | cut -c 1-8
5
Lo script “recordInsert.sh” produce quindi il seguente risultato:
$ ./recordInsert.sh Mario "Di Giovanni" "06 135 246" mdg@gmail.com
Inserito record n. 6
Da notare che sono stati utilizzati i doppi apici per delimitare quei valori che contenevano uno spazio: in questo modo la shell considera ciò che è delimitato dalle virgolette come un unico parametro, anche se nella sequenza di caratteri sono presenti degli spazi.
La seconda funzionalità da implementare è quella per la selezione dei dati dalla rubrica, con cui è possibile effettuare delle ricerche nell'archivio e visualizzare in output i risultati ottenuti. Questa funzionalità si basa sull'uso del comando esterno “grep” che, come abbiamo visto in precedenza, consente di selezionare solo alcune delle righe presenti un un file, in base alla corrispondenza con una determinata stringa o pattern. Di seguito riportiamo lo script “patternSelect.sh” che implementa la funzionalità di ricerca e visualizzazione dei dati presenti nella rubrica.
1 #!/bin/bash
2 # patternSelect.sh
3 # Riceve una stringa e visualizza in output i record che contengono
4 # la stringa (selezione "case insensitive")
5 RUBRICA=~/.rubrica
6 LABEL=(' Nome' ' Cognome' 'Telefono' ' E-mail')
7 filtro=$1
8 echo "Record selezionati: $(grep -i $filtro $RUBRICA | wc -l)"
9 echo " "
10 IFS=$'\n'
11 for record in $(grep -i $filtro $RUBRICA | sort -t \| -k 2); do
12 IFS='|'
13 i=0
14 for campo in $record; do
15 echo "${LABEL[$i]}: $campo"
16 ((i++))
17 done
18 echo " "
19 done
Con le istruzioni alle righe 5 e 6 vengono definite due variabili di configurazione dello script. La prima (RUBRICA) contiene il path ed il nome del file/archivio della rubrica degli indirizzi; la seconda variabile (LABEL) è un array che contiene la definizione delle “etichette” con i nomi dei campi dell'archivio, utilizzate per rendere più chiara la visualizzazione dei dati selezionati dalla rubrica. Alla variabile filtro viene assegnato a riga 7 il valore del primo parametro passato allo script sulla linea di comando.
La funzione di ricerca e selezione dei record nell'archivio si basa sul comando esterno “grep” ed in particolare sulla seguente istruzione, presente sia a riga 8 che a riga 11:
grep -i $filtro $RUBRICA
Con questo comando vengono selezionate dal file il cui nome è memorizzato nella variabile RUBRICA (il file “~/.rubrica” nel nostro esempio) tutte e sole le righe che contengono una sequenza di caratteri uguale a quella memorizzata nella variabile filtro, a meno del case dei caratteri, visto che è stata usata l'opzione “-i” che rende case insensitive il comando “grep”. In questo modo vengono selezionati dall'archivio i record corrispondenti al criterio di ricerca impostato dall'utente.
L'istruzione “grep” viene utilizzata due volte: la prima a riga 8 per contare il numero di record selezionati, indirizzando l'output verso il comando “wc” con un pipe ed utilizzando l'opzione “-l” per contare le righe. La seconda volta il comando “grep” viene usato per produrre una lista di stringhe (ciascun record selezionato dall'archivio è un elemento della lista) utilizzata nell'istruzione “for” a riga 11.
Il ciclo gestito dall'istruzione “for” a riga 11, esegue un'iterazione per ogni riga restituita dal comando “grep”. I record selezionati dall'archivio sono riportati ciascuno su una riga, per cui sono separati l'uno dall'altro mediante un carattere di carriage return, identificato dalla sequenza “\n”. I record dell'archivio, inoltre, possono contenere al loro interno anche dei caratteri di spaziatura. Per questo motivo, prima di eseguire il ciclo che fa variare il valore della variabile record, assegnandogli uno dopo l'altro gli elementi della lista restituita dal comando “grep”, viene ridefinita la variabile speciale IFS. Il valore assegnato alla variabile a riga 10 identifica il carattere di “ritorno a capo”: in questo modo si sostituisce in IFS il carattere di default per la separazione degli elementi di una lista.
A riga 11 l'output di “grep” viene passato, attraverso un pipe, al comando “sort” che ordina i record estratti dall'archivio in modo da consegnare all'istruzione “for” una lista ordinata alfabeticamente. I record dell'archivio contengono il cognome come secondo campo, ed il carattere con cui vengono separati i campi di un record è il simbolo “|” (pipe). Il comando “sort” viene quindi invocato con le opzioni “-t \| -k 2” che indicano che l'ordinamento deve essere eseguito sulla base del valore del secondo campo (“-k 2”) e che il carattere che separa fra loro i campi di ogni riga di input è il pipe (“-t \|”). Da notare che, siccome il carattere “|” ha un significato ben preciso per la Bash, affinché non venga interpretato come l'operatore pipe, viene preceduto da un carattere backslash “\”.
Per ogni elemento della lista restituita da “grep” lo script suddivide la stringa in singoli campi e stampa in output ciascun campo del record. Per far questo viene modificato ancora una volta il valore della variabile speciale IFS, impostandolo con il carattere pipe (riga 12), utilizzato come separatore dei campi contenuti nei record della rubrica. Con il ciclo “for” di riga 14, vengono così selezionati, uno dopo l'altro, i campi del record e vengono visualizzati in output, preceduti dall'etichetta che identifica ciascun campo e che, per semplicità, è memorizzata nella componente i-esima dell'array LABEL.
Considerando la rubrica degli indirizzi riportata in precedenza, di seguito viene presentato un esempio di output prodotto dallo script:
$ ./patternSelect.sh Liverani
Nome: Marco
Cognome: Liverani
Telefono: 06 123 456
E-mail: m.liverani@aquilante.net
Naturalmente non c'è mai un solo modo per risolvere un problema con uno script. A titolo di esempio riportiamo di seguito uno script differente, che produce lo stesso risultato del precedente. In questo caso la soluzione proposta è incentrata sull'uso del comando esterno “awk” per la separazione e la visualizzazione dei singoli campi dei record selezionati con “grep”.
1 #!/bin/bash
2 # patternSelectBis.sh
3 # Riceve una stringa e visualizza in output i record che contengono
4 # la stringa (selezione "case insensitive") utilizzando awk
5 RUBRICA=~/.rubrica
6 filtro=$1
7 echo "Record selezionati: $(grep -i $filtro $RUBRICA | wc -l)"
8 echo " "
9 grep -i $filtro $RUBRICA | sort -t \| -k 2 | awk '{ split($1,a,"|");\
10 printf " Nome: %s\n Cognome: %s\nTelefono: %s\n \
11 E-mail: %s\n\n", a[1], a[2], a[3], a[4] }'
Come scrive Alfred Aho, uno dei tre autori di AWK\footnote{Gli altri due sono Peter Weinberger e Brian Kernighan, da cui l'acronimo AWK con cui è stato denominato il programma, utilizzando le iniziali dei cognomi dei tre autori.}, AWK è un linguaggio per elaborare file di testo. Un file viene trattato da AWK come una sequenza di record, e ogni riga del file è un record. Ogni riga viene suddivisa in una sequenza di campi: possiamo pensare alla prima parola nella riga del file come al primo campo, alla seconda parola come al secondo campo, e così via. Un programma in AWK è una sequenza di istruzioni costituite da un pattern e da un'azione. AWK legge il file in input una riga alla volta e analizza la riga per verificare se corrisponde con uno dei pattern del programma; per ciascun pattern individuato, viene eseguita l'azione corrispondente.
Nel nostro caso il comando “awk” viene utilizzato in modo molto elementare, definendo un'azione molto semplice da applicare a tutte le stringhe che corrispondono ad un pattern nullo: la selezione dei record ed il loro successivo ordinamento alfabetico, sono infatti operazioni affidate ai comandi “grep” e “sort”, il cui output viene alla fine fornito ad “awk” mediante l'operatore pipe.
Lo script “awk” viene riportato sulla riga di comando (spezzata su tre righe, nel nostro esempio, per ragioni di spazio) delimitato da apici. Al suo interno i comandi che costituiscono l'azione da eseguire sono delimitati da parentesi graffe. Tali comandi eseguono la suddivisione (“split”) in campi della riga letta in input e la visualizzazione in output (“printf”) dei quattro campi memorizzati in altrettante celle dell'array a. Il comando “split” del linguaggio AWK accetta infatti tre argomenti: la stringa da suddividere in campi, il nome di un array in cui memorizzare i singoli campi e il carattere utilizzato come delimitatore dei campi (nel nostro esempio il simbolo “|”).
Per concludere possiamo riportare una terza versione dello script per la ricerca e la visualizzazione dei dati presenti nella rubrica, in cui la selezione dei record avviene direttamente con il comando “awk”, senza l'uso di “grep”.
1 #!/bin/bash
2 # patternSelectTer.sh
3 # Riceve una stringa e visualizza in output i record che contengono
4 # la stringa utilizzando awk
5 RUBRICA=~/.rubrica
6 filtro=$1
7 echo "Record selezionati: $(grep -i $filtro $RUBRICA | wc -l)"
8 echo " "
9 sort -t \| -k 2 $RUBRICA | awk '/'$filtro'/ {split($1,a,"|"); \
10 printf " Nome: %s\n Cognome: %s\nTelefono: %s\n \
11 E-mail: %s\n\n", a[1], a[2], a[3], a[4]}'
In questo caso il comando “sort” esegue l'ordinamento alfabetico dell'intera rubrica in base al cognome, quindi l'output viene passato attraverso un pipe ad “awk” che applica l'azione di suddivisione e visualizzazione dei campi solo ai record che corrispondono con il pattern fornito dall'utente, memorizzato come al solito nella variabile filtro.
Il comando “awk” in quest'ultimo esempio viene utilizzato fornendogli uno script in una forma più generale, del tipo
awk '/pattern/ { azione }'
con cui viene eseguito il confronto tra il pattern ed ogni riga ricevuta in input e, nel caso in cui l'esito del confronto sia positivo, viene eseguita l'azione codificata con le istruzioni delimitate dalle parentesi graffe.
L'ultima funzionalità che deve essere implementata riguarda la cancellazione di record dall'archivio. Proponiamo di seguito una soluzione molto semplice: acquisita in input sulla linea di comando una stringa che costituisce il criterio di selezione dei record da eliminare, si utilizza il comando “grep” con l'opzione “-v” per selezionare tutte le righe del file-rubrica che non contengono la stringa specificata dall'utente; il file con l'archivio degli indirizzi viene riscritto completamente solo con le righe selezionate da “grep” e, in questo modo, vengono di fatto eliminati i record (le righe del file) che contengono la stringa fornita dall'utente.
1 #!/bin/bash
2 # patternDelete.sh
3 # Riceve una stringa ed elimina dall'archivio tutti i record
4 # che la contengono
5 RUBRICA=~/.rubrica
6 filtro=$1
7 if [ $filtro ]; then
8 n=$(grep $filtro $RUBRICA|wc -l)
9 grep -v $filtro $RUBRICA > $RUBRICA.new
10 mv $RUBRICA $RUBRICA.old
11 mv $RUBRICA.new $RUBRICA
12 echo "Record eliminati: $n"
13 else
14 echo "$0: ERRORE: non e' stato specificato nessun filtro"
15 exit 1
16 fi
Per evitare di eliminare tutti i record dall'archivio per una semplice disattenzione da parte dell'utente, le istruzioni per la cancellazione delle righe dal file sono incluse in una struttura di controllo condizionale implementata dall'istruzione “if-else”; in questo modo si verifica, con la condizione a riga 7, che il pattern per la selezione dei record da eliminare non sia nullo.
Se il valore della variabile filtro non è nullo, viene creato un nuovo file, il cui nome ha estensione “.new”, con i record che non contengono la stringa memorizzata nella variabile filtro (riga 9). Quindi viene modificato il nome del vecchio file di archivio aggiungendo l'estensione “.old” (riga 10) e viene infine rinominato il nuovo archivio con un nome privo dell'estensione “.new” (riga 11).
Se invece la variabile filtro ha valore nullo (nessuna stringa è stata passata allo script sulla linea di comando), viene visualizzato un messaggio di errore (riga 14) e lo script termina con un return code diverso da zero (riga 15).
A questo punto è possibile costruire uno script unico, che contenga tutte le funzionalità descritte nelle pagine precedenti.
Lo script viene progettato per operare sia in modalità “batch” che interattiva: se viene fornita sulla linea di comando un'opzione corrispondente ad una delle funzionalità implementate, lo script acquisisce i parametri sulla stessa linea di comando ed esegue la funzione corrispondente. Se invece viene lanciato senza alcun parametro sulla command line, lo script viene eseguito in modalità interattiva, con la possibilità di attivare le diverse funzionalità selezionando l'opzione corrispondente da un menù principale.
Il codice sorgente degli script visti nelle pagine precedenti, viene inglobato nel corpo di tre diverse funzioni: “recordInsert” per l'inserimento di un nuovo record in archivio, “patternDelete” per la cancellazione di uno o più record dall'archivio e “patternSelect” per la ricerca in archivio e la visualizzazione dei record selezionati.
Di seguito riportiamo il codice sorgente dell'intero script: come risulterà immediatamente evidente, il corpo delle tre funzioni è identico agli script riportati nelle pagine precedenti, a meno della definizione delle variabili RUBRICA e LABEL, che avviene alle righe 8 e 9, una volta per tutte per l'intero script.
1 #!/bin/bash
2 # rubrica.sh
3 # Rubrica telefonica interattiva.
4 #
5 # Variabili di configurazione globali
6 #
7 RUBRICA=~/.rubrica
8 LABEL=(' Nome' ' Cognome' 'Telefono' ' E-mail')
9 #
10 # Funzione: recordInsert
11 # Riceve come argomento nome, cognome, telefono e e-mail
12 # e li inserisce in un nuovo record della rubrica
13 #
14 function recordInsert {
15 nome=$1
16 cognome=$2
17 telefono=$3
18 email=$4
19 echo "$nome|$cognome|$telefono|$email" >> $RUBRICA
20 echo "Inserito record n. $(wc -l $RUBRICA | cut -c 1-8)"
21 }
22 #
23 # Funzione: patternDelete
24 # Riceve una stringa ed elimina dalla rubrica tutti i record
25 # che contengono esattamente quella stringa
26 #
27 function patternDelete {
28 filtro=$1
29 if [ $filtro ]; then
30 n=$(grep $filtro $RUBRICA|wc -l)
31 grep -v $filtro $RUBRICA > $RUBRICA.new
32 mv $RUBRICA $RUBRICA.old
33 mv $RUBRICA.new $RUBRICA
34 echo "Record eliminati: $n"
35 else
36 echo "$0: ERRORE: non e' stato specificato nessun filtro"
37 exit 1
38 fi
39 }
40 #
41 # Funzione: patternSelect
42 # Riceve una stringa e visualizza in output i record che contengono
43 # la stringa (selezione "case insensitive")
44 #
45 function patternSelect {
46 filtro=$1
47 echo "Record selezionati: $(grep -i $filtro $RUBRICA | wc -l)"
48 echo " "
49 IFS=$'\n'
50 for record in $(grep -i $filtro $RUBRICA | sort -t \| -k 2); do
51 IFS='|'
52 i=0
53 for campo in $record; do
54 echo "${LABEL[$i]}: $campo"
55 ((i++))
56 done
57 echo " "
58 done
59 }
60 #
61 # Procedura principale
62 #
63 opt=$1
64 # Se viene passata un'opzione sulla riga di comando
65 # opera in modalita' batch
66 if [ $opt ]; then
67 case $opt in
68 -h)
69 echo "Rubrica degli indirizzi"
70 echo " "
71 echo "usage: $0 [-h|-i|-d|-f] [params]"
72 echo " "
73 echo " -h : help"
74 echo " -i : insert ('$0 -i nome cognome telefono e-mail')"
75 echo " -d : delete ('$0 -d pattern')"
76 echo " -f : find ('$0 -f pattern')"
77 echo " ";;
78 -i)
79 recordInsert $2 $3 $4 $5;;
80 -d)
81 patternDelete $2;;
82 -f)
83 patternSelect $2;;
84 *)
85 echo "ERRORE: opzione non prevista";;
86 esac
87 # Altrimenti visualizza un menu' interattivo
88 else
89 PS3='--> '
90 clear
91 echo "RUBRICA INDIRIZZI"
92 select s in 'Inserimento record' 'Eliminazione record' \
93 'Ricerca record' 'Quit'; do
94 case $REPLY in
95 (1)
96 echo " "
97 echo "Inserimento nuovo record"
98 for (( i=0; i<4; i++)); do
99 echo -n "${LABEL[$i]}: "
100 read a[$i]
101 done
102 recordInsert "${a[0]}" "${a[1]}" "${a[2]}" "${a[3]}";;
103 (2)
104 echo " "
105 echo "Eliminazione record"
106 echo -n "Inserisci una stringa: "
107 read s
108 patternDelete $s;;
109 (3)
110 echo " "
111 echo "Ricerca record"
112 echo -n "Inserisci una stringa: "
113 read s
114 patternSelect $s;;
115 (4)
116 clear
117 exit 0;;
118 (*)
119 echo "Opzione errata";;
120 esac
121 done
122 fi
Il corpo principale dello script, da riga 60 in poi, è costituito da due parti distinte, gestite dalla struttura condizionale implementata dall'istruzione “if-else” alle righe 66 e 88. Alla variabile opt viene assegnato il primo dei parametri passati allo script sulla linea di comando (istruzione a riga 63). La condizione permette di controllare se il valore della variabile opt è nullo oppure no. In quest'ultimo caso, se la variabile ha un valore non nullo, significa che l'utente ha specificato delle opzioni sulla command line invocando lo script, quindi il programma opera in modalità batch in base all'opzione specificata dall'utente (righe 67--86). In caso contrario, se l'utente non ha specificato alcun parametro sulla riga di comando, lo script opera in modalità interattiva presentando un menù di opzioni all'utente (righe 88--122).
Le opzioni disponibili per il funzionamento in modalità batch sono quattro:
La selezione dell'opzione viene gestita mediante l'istruzione “case” (riga 67): in corrispondenza alle tre opzioni per l'inserimento, la cancellazione e la ricerca di record, vengono richiamate le rispettive funzioni passando come argomento i parametri forniti dall'utente sulla linea di comando.
La modalità interattiva viene implementata invece mediante l'istruzione “select” (righe 92--93) che presenta e gestisce un menù con quattro scelte: inserimento di un nuovo record, eliminazione di record, ricerca di record e chiusura del programma.
Anche in questo caso la scelta effettuata dall'utente viene gestita attraverso l'istruzione “case”: per ciascuna opzione vengono acquisiti in input mediante l'istruzione “read” tutti i dati necessari per eseguire la funzione selezionata dall'utente, che vengono poi passati come argomento alla funzione corrispondente.
Di seguito, per concludere, riportiamo un esempio di sessione di lavoro con lo script.
$ ./rubrica.sh -h
Rubrica degli indirizzi
usage: ./rubrica.sh [-h|-i|-d|-f] [params]
-h : help
-i : insert ('./rubrica.sh -i nome cognome telefono e-mail')
-d : delete ('./rubrica.sh -d pattern')
-f : find ('./rubrica.sh -f pattern')
$ ./rubrica.sh
RUBRICA INDIRIZZI
1) Inserimento record 3) Ricerca record
2) Eliminazione record 4) Quit
--> 1
Inserimento nuovo record
Nome: Mario
Cognome: Rossi
Telefono: 02 345 678
E-mail: mario.rossi@pluto.com
Inserito record n. 6
--> 3
Ricerca record
Inserisci una stringa: rossi
Record selezionati: 1
Nome: Mario
Cognome: Rossi
Telefono: 02 345 678
E-mail: mario.rossi@pluto.com
--> 2
Eliminazione record
Inserisci una stringa: rossi
Record eliminati: 1
-->
1) Inserimento record 3) Ricerca record
2) Eliminazione record 4) Quit
--> 4
Navigando sul web spesso vengono visualizzati dei contenuti “statici”, ossia che non cambiano nel tempo, come la pagina web contenente un libro o un manuale on-line; in altri casi, invece, il contenuto visualizzato utilizzando il web browser per navigare sulla rete Internet, non è “statico”, ma “dinamico”, ossia viene generato al momento della richiesta da un programma. Uno script CGI non è altro che un programmino che viene lanciato da un server HTTP quando, mediante un web browser, viene invocata una determinata URL gestita da tale server.
Quando eseguiamo una ricerca con Google, inseriamo delle parole in un campo di una form visualizzata mediante il web browser e quindi selezioniamo con il mouse il bottone che avvia la procedura di ricerca negli archivi di Google. Il risultato della nostra ricerca viene visualizzato su una pagina del browser: in questo caso si tratta di un contenuto “dinamico”, prodotto in base ai criteri di ricerca che abbiamo inserito nella form. Selezionando il bottone “Cerca con Google” abbiamo inviato al server HTTP di Google le parole che costituiscono i nostri criteri di ricerca; il server Google esegue un programma che, ricevute tali parole, effettua la ricerca su un archivio e presenta in output il risultato; il server HTTP di Google invia il risultato al nostro web browser. In poche parole, e con qualche semplificazione, abbiamo descritto il processo con cui operano la maggior parte degli applicativi web based; un modo per realizzare un programma del genere è quello di scrivere uno script CGI.
Il processo di chiamata del programma CGI e restituzione dell'output
HTTP, HyperText Transfer Protocol è il protocollo di comunicazione applicativo mediante cui vengono inviate le richieste dai web browser ai web server e vengono restituiti i contenuti multimediali di risposta dai web server ai web browser.
Le pagine web sono codificate con un linguaggio di marcatura del testo chiamato HTML, HyperText Mark-up Language. HTML non è un linguaggio di programmazione, ma un linguaggio con cui si possono inserire delle parole chiave all'interno di un testo, in modo tale da definire la struttura logica del documento e da caratterizzarne alcune parole o intere frasi. Ad esempio con HTML è possibile marcare alcune frasi come titoli di capitoli o di sezioni, è possibile evidenziare delle parole importanti, è possibile definire degli elenchi puntati o numerati e delle tabelle; è anche possibile definire dei riferimenti incrociati all'interno di uno stesso file o tra file differenti, in modo da trasformare un testo rigidamente sequenziale in un ipertesto. Con HTML è possibile anche inserire i riferimenti di un'immagine in formato digitale all'interno di un file di testo.
I riferimenti ipertestuali ad altri documenti o contenuti multimediali (immagini, filmati, ecc.), vengono espressi in un formato noto come URI, Uniform Resource Identifier, con cui ogni singolo file o documento presente in rete può essere identificato univocamente. Nel formato URI sono espresse le URL, Uniform Resource Locator, che esprimono gli indirizzi delle risorse presenti sul web. Una tipica URL è una stringa nel seguente formato:
http://www.aquilante.net/bash/index.shtml
che identifica univocamente un file denominato “index.shtml”, presente nella directory “/bash” sul server “www.aquilante.net”, accessibile mediante il protocollo “http”.
L'interfaccia CGI, Common Gateway Interface, è una specifica tecnica che permette di interfacciare un server HTTP con un programma che viene eseguito sullo stesso server. La specifica tecnica definisce il modo in cui i dati vengono passati dal server HTTP al programma CGI e il modo con cui l'output prodotto dal programma viene ricevuto dal server HTTP per poi essere spedito al browser dell'utente per la visualizzazione.
L'interfaccia CGI è uno strumento assai semplice, ma non particolarmente efficiente: si presta bene a realizzare rapidamente applicazioni web based semplici o con una bassa mole di traffico, mentre non è adatta per realizzare applicazioni complesse in grado di reggere il carico di centinaia o migliaia di connessioni contemporanee da parte di numerosi utenti. Per la sua semplicità è possibile comunque realizzare dei programmi anche con linguaggi di programmazione molto elementari, come Bash.
Nel seguito faremo l'ipotesi di disporre di un server HTTP, ad esempio Apache HTTP Server, configurato in modo tale da poter eseguire script CGI. Negli esempi che seguono il server HTTP sarà eseguito sulla stessa macchina su cui gira il web browser, per cui l'accesso agli script sarà effettuato con URL del tipo “http://localhost/...”.
L'interfaccia CGI, come abbiamo detto, si occupa gestire il passaggio dei parametri dal server HTTP all'applicazione CGI e, al termine dell'esecuzione di quest'ultima, di catturare l'output prodotto su standard output e di passarlo al server HTTP. L'utente infatti non interagisce con lo script attraverso la command line del proprio terminale, ma mediante un web browser che comunica con il web server usando il protocollo HTTP. Per cui l'utente non è nelle condizioni di visualizzare ciò che lo script produce su standard output, a meno che questo non venga catturato ed inviato al web browser come risposta ad una richiesta HTTP: l'interfaccia CGI si occupa anche di questo.
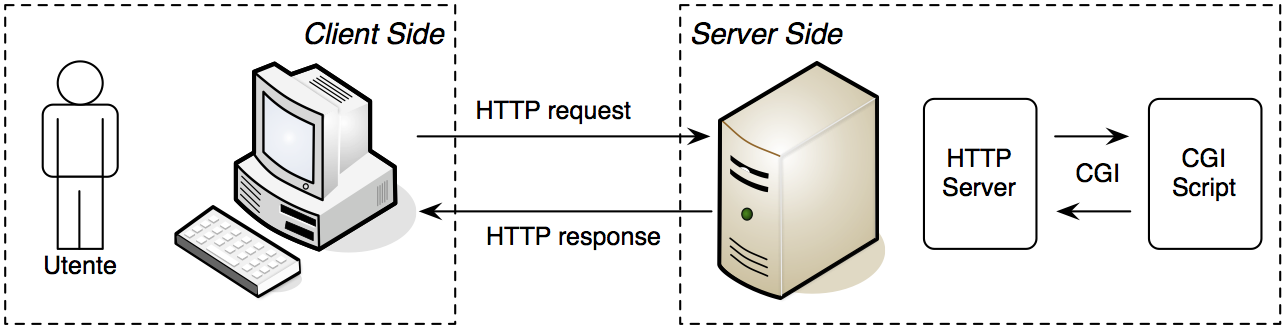
Schematizzazione dello scambio di dati dal web browser al web server attraverso il protocollo HTTP e dal web server allo script attraverso l'interfaccia CGI
L'utente può fornire un input ad uno script CGI, ad esempio compilando i campi di una web form. I dati inseriti in input dall'utente vengono raccolti dal web browser e trasformati in una stringa in formato URL-encoded. Tale formato prevede, tra l'altro, che i parametri siano concatenati fra loro delimitandoli con il carattere “&” e che ciascun dato sia espresso nella forma “nome=valore”. La stringa deve essere priva di spazi, per cui ciascun carattere di spaziatura viene trasformato nel simbolo “+”; altre trasformazioni vengono effettuate per codificare i caratteri con un codice ASCII maggiore di 127 (tra questi le lettere accentate ed altri simboli).
Ad esempio se l'utente fornisce in input i dati “nome”, “cognome”, “email”, con i rispettivi valori “Marco”, “Liverani”, “m.liverani@aquilante.net”, questi saranno raccolti dal browser e trasformati nella seguente stringa in formato URL-encoded:
nome=Marco&cognome=Liverani&email=m.liverani@aquilante.net
I dati, codificati in formato URL-encoded, vengono passati al web server attraverso uno dei due meccanismi previsti dal protocollo HTTP: il metodo “GET” o il metodo “POST”. Nel primo caso la stringa con i parametri viene concatenata alla URL, utilizzando il carattere “?” come separatore; ad esempio:
http://localhost/~marco/script.cgi?nome=Marco&cognome=Liverani&...
Nel caso del metodo POST, invece, la stringa in formato URL-encoded viene accodata alla richiesta HTTP senza essere mostrata nella URL.
Il server web, attraverso l'interfaccia CGI, rende disponibile la stringa dei parametri allo script in due modi diversi, a seconda del metodo HTTP usato per il passaggio dei parametri. Il metodo utilizzato viene indicato nella variabile d'ambiente REQUEST_METHOD, che assumerà il valore “GET” o “POST” a seconda dei casi. Se è stato usato il metodo GET, la stringa viene memorizzata nella variabile d'ambiente QUERY_STRING, resa disponibile allo script CGI. Nel caso in cui, invece, sia stato usato il metodo POST, la stringa con i parametri viene passata allo script CGI direttamente attraverso il canale standard input.
Nel restituire l'output al server HTTP, lo script CGI dovrà semplicemente produrre una pagina in formato HTML su standard output, preceduta da una riga contenente la seguente stringa, seguita da una riga completamente vuota:
Content-Type: text/html
L'output prodotto in questo modo verrà catturato attraverso l'interfaccia CGI dal server HTTP e da questi inviato al web browser.
Un primo esempio banale è quello di uno script che visualizza in output la data e l'ora corrente. Uno script di questo tipo non ha bisogno di acquisire in input alcun parametro e per questo è particolarmente facile implementarlo. Riportiamo di seguito il codice dello script.
1 #!/bin/bash
2 # data.cgi
3 # Lo script produce in output la data e l'ora corrente.
4 data=$(date +%d/%m/%Y)
5 ora=$(date +%H:%M)
6 echo "Content-Type: text/html"
7 echo
8 echo "<html>"
9 echo "<head><title>Data e ora</title></head>"
10 echo "<body><p>Oggi e' il $data e sono le $ora</p></body>"
11 echo "</html>"
Una volta copiato lo script in una directory compatibile con la configurazione del server HTTP (es.: la directory “~/public_html” su una macchina UNIX con server web Apache), abilitando l'esecuzione dello script (es.: “chmod 755 data.cgi”), è possibile verificarne il corretto funzionamento utilizzando un web browser, come nell'esempio in Figura.
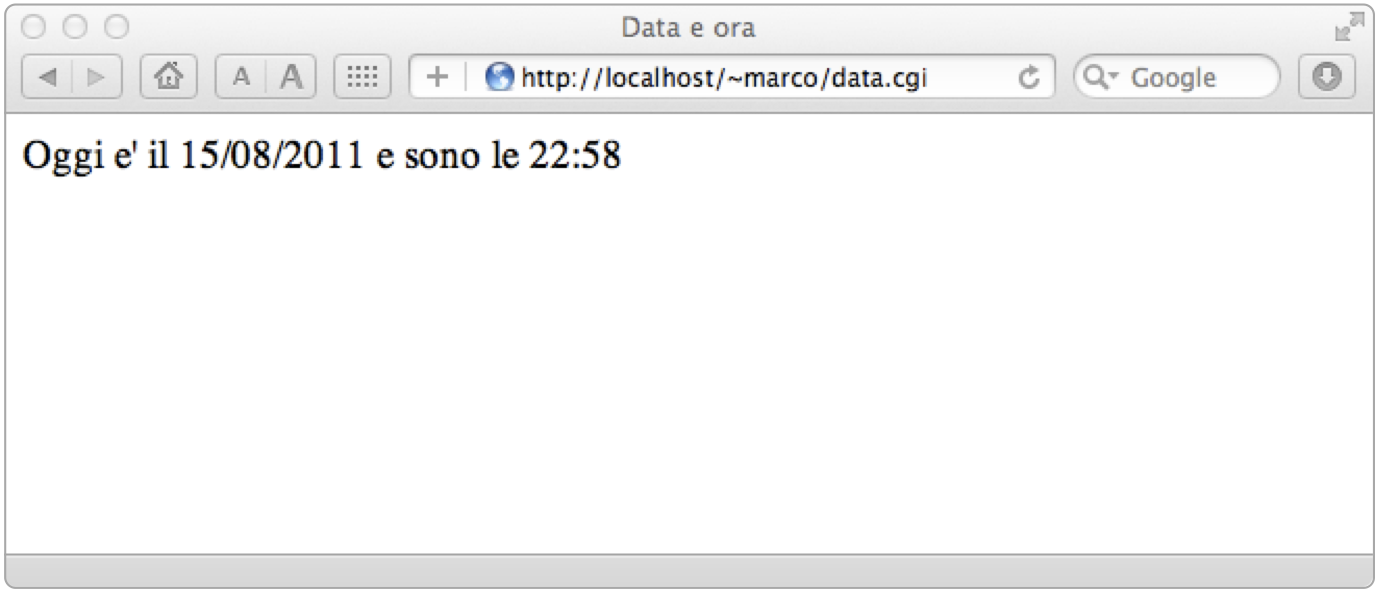
L'output prodotto dallo script CGI “data.cgi”
Il passo successivo è quello di implementare le funzioni necessarie ad acquisire dei parametri dall'interfaccia CGI. Innanzi tutto predisponiamo una pagina HTML con una form in cui possano essere inseriti dei dati da passare ad uno script CGI.
La pagina del nostro esempio presenta due campi di testo: uno per l'inserimento di un nome ed uno per l'inserimento di un cognome; la form è corredata dai due tipici bottoni “Submit” e “Reset”: uno per il completamento della compilazione della form e l'invio dei dati allo script CGI e l'altro per il ripristino dello stato iniziale dei campi. Il codice sorgente in HTML è riportato di seguito.
1 <html>
2 <head>
3 <title>Inserimento dati</title>
4 </head>
5 <body>
6 <p>Inserisci i dati e premi il bottone Submit:</p>
7 <form action="param.cgi" method="GET">
8 <p>Nome: <input name="nome"></p>
9 <p>Cognome: <input name="cognome"></p>
10 <p><input type="submit"> <input type="reset"></p>
11 </form>
12 </body>
13 </html>
Da notare che a riga 7, il tag “form” presenta due attributi molto importanti: il primo è l'attributo “action” con cui deve essere specificata la URL dello script CGI che deve essere richiamato quando l'utente avrà completato la compilazione della form ed avrà premuto il bottone “Submit”.
L'attributo “method”, invece, consente di specificare il metodo HTTP con cui devono essere passati i dati inseriti nella form allo script CGI: il valore dell'attributo “method” deve essere quindi “GET” (come nell'esempio) o “POST”.
I campi della form sono due, identificati dai nomi “nome” e “cognome”, specificati con l'attributo “name” del tag “input”. Quindi i dati inseriti dall'utente nella form saranno spediti al server HTTP con una stringa URL-encoded con il seguente formato:
nome=nome inserito dall'utente&cognome=cognome inserito dall'utente
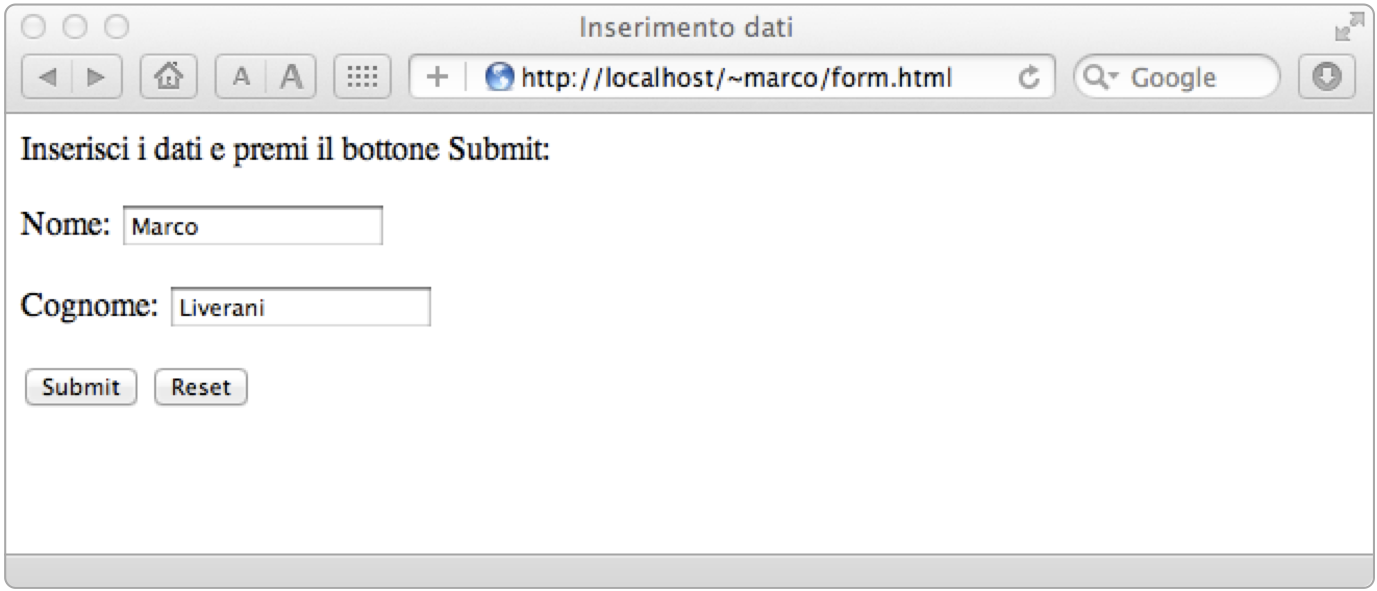
La semplice form HTML per l'invio di due parametri ad uno script CGI
A questo punto bisogna codificare una funzione Bash che consenta di acquisire i parametri passati dal server HTTP allo script attraverso l'interfaccia CGI. Come abbiamo detto la stringa con i parametri, in formato URL-encoded, viene resa disponibile allo script nella variabile d'ambiente QUERY_STRING oppure mediante il canale di standard input a seconda del metodo scelto per il passaggio dei parametri, rispettivamente “GET” o “POST”.
Di seguito riportiamo il codice sorgente della funzione Bash “getCgiString” che acquisisce la stringa URL-encoded e la restituisce in output su standard output.
1 function getCgiString {
2 local stringa
3 if [ "$REQUEST_METHOD" == "GET" ]; then
4 stringa=$QUERY_STRING
5 else
6 read stringa
7 fi
8 stringa=$(echo $stringa | sed "s/\+/ /g")
9 echo "$stringa"
10 }
A riga 2 viene verificato il valore della variabile d'ambiente REQUEST_METHOD impostata dal server HTTP: se il valore è “GET”, alla variabile stringa viene assegnato il valore della variabile d'ambiente QUERY_STRING, altrimenti a riga 5 viene letta da standard input una stringa di caratteri, che viene memorizzata nella variabile stringa.
Con l'istruzione presente a riga 8, viene parzialmente decodificato il formato URL-encoded della stringa memorizzata nella variabile stringa, trasformando tutti i caratteri “+” in caratteri di spaziatura. Per far questo il valore di stringa viene passato in input mediante l'operatore pipe dal comando “echo” al comando esterno “sed”.
Il comando “sed” accetta sulla linea di comando una stringa che rappresenta un'espressione regolare con cui deve essere elaborata la sequenza di caratteri ricevuta in input. Un'espressione regolare è una stringa che, attraverso dei meta-caratteri, consente di definire un pattern che identifica un'insieme di stringhe. Per maggiori informazioni sulla sintassi delle espressioni regolari gestite da “sed” si suggerisce di fare riferimento alla pagina di manuale (“man sed”).
Nell'istruzione riportata a riga 8 al comando “sed” viene passata come argomento l'espressione “s/\+/ /g”, che indica che tutte le occorrenze di una certa stringa devono essere sostituite con un'altra stringa. Il carattere “s” all'inizio dell'espressione indica che si richiede a “sed” di effettuare una sostituzione; la stringa da cercare è descritta dall'espressione regolare delimitata dalla prima coppia di caratteri “/”; tale stringa è costituita dal carattere “+” identificato dalla sequenza “\+”, dal momento che il carattere “+” ha un significato speciale nel contesto delle espressioni regolari. La stringa da sostituire ad ogni occorrenza del pattern è delimitata dalla seconda coppia di caratteri “/” (lo spazio). Il carattere “g” al termine dell'espressione indica che la sostituzione deve essere eseguita globalmente, per ogni occorrenza della prima stringa e non solo per la prima occorrenza.
Ad esempio, se viene passata in input al comando “sed "s/\+/ /g"” la stringa “aaa+bbb+ccc”, si ottiene in output la stringa “aaa bbb ccc”, come rappresentato nella figura seguente. Naturalmente la decodifica del formato URL-encoded è del tutto incompleta e dunque, al di là dell'esempio riportato in queste pagine, la funzione “getCgiString” andrebbe implementata ulteriormente, per renderla più robusta ed efficace, permettendo una decodifica completa di tutti i meta-caratteri utilizzati nella codifica URL-encoding.
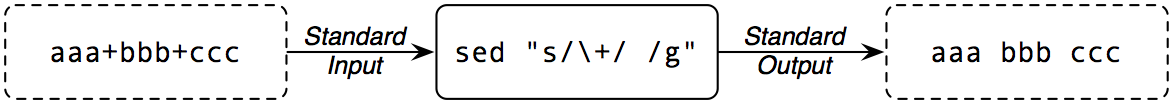
Un esempio del funzionamento del comando “sed”
Una prima versione dello script “param.cgi” che riceve ed utilizza i parametri forniti dall'utente mediante la form HTML, può essere implementata facendo uso della funzione “getCgiString”. Di seguito ne riportiamo il codice sorgente.
1 #!/bin/bash
2
3 function getCgiString {
4 local stringa
5 if [ "$REQUEST_METHOD" == "GET" ]; then
6 stringa=$QUERY_STRING
7 else
8 read stringa
9 fi
10 stringa=$(echo $stringa | sed "s/\+/ /g")
11 echo "$stringa"
12 }
13
14 dati=$(getCgiString)
15 echo "Content-Type: text/html"
16 echo
17 echo "<html>"
18 echo "<head><title>Parametri</title></head>"
19 echo "<body>"
20 echo "<p>Dati in input: '$dati'</p>"
21 echo "</body>"
22 echo "</html>"
A riga 14 viene invocata la funzione “getCgiString” memorizzando la stringa URL-encoded con i parametri prodotta in output, nella variabile dati. Poi viene generata dinamicamente una pagina HTML in cui viene presentata la stringa di parametri ricevuta mediante l'interfaccia CGI (riga 20). In Figura viene presentato l'output prodotto da questo script.
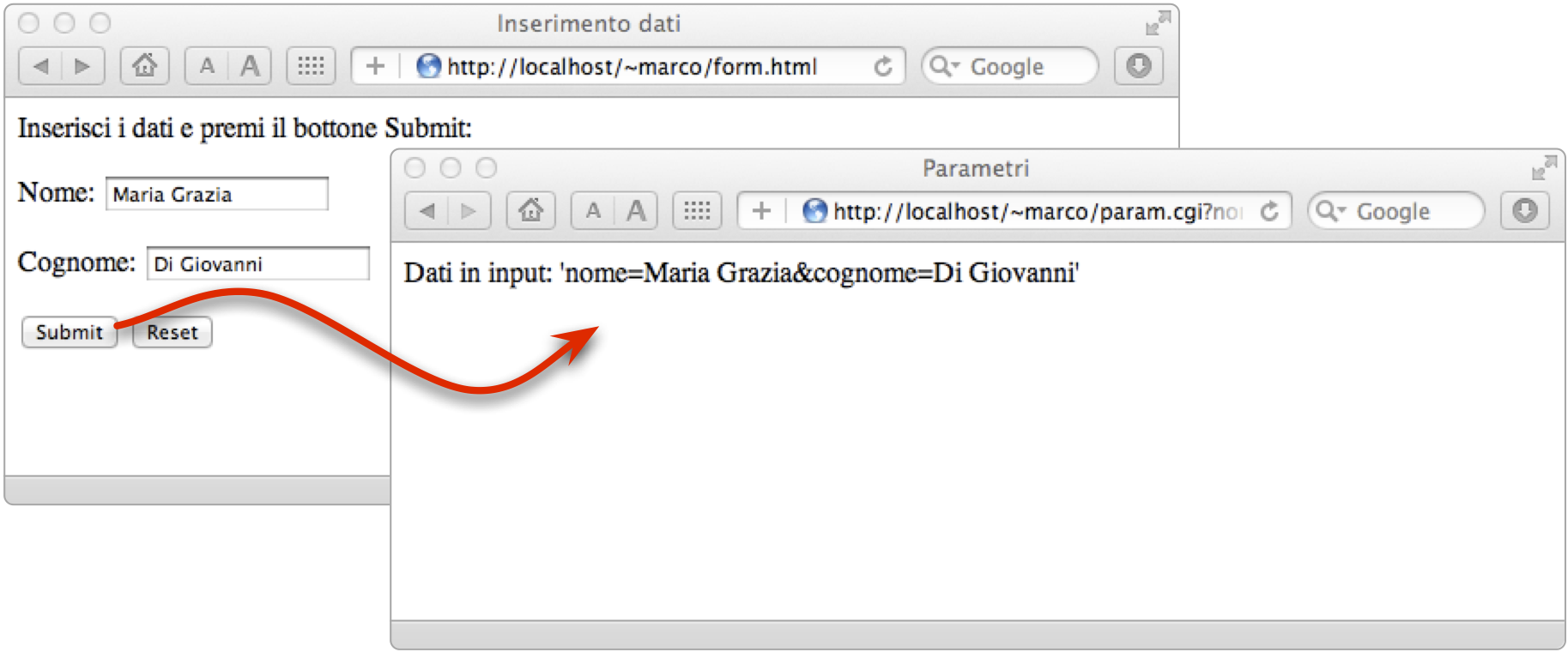
Dalla pagina “form.html” viene richiamato lo script “param.cgi” passando i dati inseriti dall'utente nei campi della form; lo script CGI visualizza i dati ricevuti attraverso l'interfaccia CGI come un'unica stringa di testo
Per poter utilizzare i dati forniti in input allo script mediante l'interfaccia CGI è necessario predisporre una funzione in grado di estrarre i valori dei singoli parametri dalla stringa URL-encoded.
Di seguito riportiamo il codice sorgente della funzione “getCgiParam” che, ricevuto come argomento il nome del parametro che si intende estrarre e la stringa URL-encoded, restituisce il valore del parametro su standard output. Ad esempio, se la stringa URL-encoded è “nome=Marco&cognome=Liverani”, la seguente istruzione:
getCgiParam cognome "nome=Marco&cognome=Liverani"
produce in output il valore “Liverani”.
1 function getCgiParam {
2 local nome stringa a oldIFS cgiValue
3 nome=$1
4 stringa=$2
5 oldIFS=$IFS
6 IFS="&"
7 for parametro in $stringa; do
8 IFS="="
9 a=($parametro)
10 if [ "${a[0]}" == "$nome" ]; then
11 cgiValue=${a[1]}
12 break
13 fi
14 IFS="&"
15 done
16 IFS=$oldIFS
17 echo "$cgiValue"
18 }
La funzione, dopo aver ridefinito la variabile speciale IFS in cui è memorizzato il carattere utilizzato da Bash per separare gli elementi di una lista, impostando come valore il carattere “&” (riga 6), esegue una iterazione su ogni elemento della stringa URL-encoded: in questo caso gli elementi della lista sono le stringhe “nome=valore” separate l'una dall'altra dal carattere “&”, memorizzate nella variabile parametro ad ogni iterazione del ciclo “for”.
A riga 8 viene quindi ridefinita la variabile IFS impostando come valore il carattere “=”. In questo modo il valore della variabile parametro viene considerata come una lista composta da due elementi: il primo è il nome del parametro passato attraverso l'interfaccia CGI, il secondo è il valore di tale parametro. Con l'istruzione “a=($parametro)” di riga 9, si costruisce un array “a” con due elementi: il nome del parametro (a[0]) e il suo valore (a[1]).
Se il valore di a[0] coincide con il nome del parametro che si intende estrarre dalla stringa (riga 10), il valore di a[1] viene memorizzato nella variabile cgiValue (riga 11). Al termine della funzione viene restituito in output il valore di cgiValue (riga 17).
Utilizzando anche la funzione “getCgiParam” possiamo migliorare lo script precedente che, ricevuti dei dati da una form, li presenta in output. La form è la stessa già vista in precedenza, che consente di acquisire in input i campi nome e cognome. Lo script è riportato di seguito.
1 #!/bin/bash
2 # param.cgi
3 # Visualizza i parametri "nome" e "cognome" passati attraverso
4 # l'interfaccia CGI
5 #
6 # Funzione: getCgiParam
7 # Estrae dalla stringa dei parametri quello il cui nome corrisponde
8 # con l'argomento della funzione; restituisce in output il valore
9 # del parametro
10 #
11 function getCgiParam {
12 local nome stringa a oldIFS cgiValue
13 nome=$1
14 stringa=$2
15 oldIFS=$IFS
16 IFS="&"
17 for parametro in $stringa; do
18 IFS="="
19 a=($parametro)
20 if [ "${a[0]}" == "$nome" ]; then
21 cgiValue=${a[1]}
22 break
23 fi
24 IFS="&"
25 done
26 IFS=$oldIFS
27 echo "$cgiValue"
28 }
29 #
30 # Funzione: getCgiString
31 # Acquisisce i parametri passati allo script attraverso l'interfaccia
32 # CGI e restituisce in output la stringa in formato URL-encoded
33 #
34 function getCgiString {
35 local stringa
36 if [ "$REQUEST_METHOD" == "GET" ]; then
37 stringa=$QUERY_STRING
38 else
39 read stringa
40 fi
41 stringa=$(echo $stringa | sed "s/\+/ /g")
42 echo "$stringa"
43 }
44 #
45 # Corpo principale dello script
46 #
47 stringa=$(getCgiString)
48 nome=$(getCgiParam nome $stringa)
49 cognome=$(getCgiParam cognome $stringa)
50 echo "Content-Type: text/html"
51 echo
52 echo "<html>"
53 echo "<head><title>Parametri</title></head>"
54 echo "<body>"
55 echo "<p>Dati in input: '$stringa'</p>"
56 echo "<p>Nome: '$nome'</p>"
57 echo "<p>Cognome: '$cognome'</p>"
58 echo "</body>"
59 echo "</html>"
Un esempio di output prodotto dallo script “param.cgi” è riportato nella figura seguente. Di fatto, dopo aver affidato alle funzioni “getCgiParam” e “getCgiString” l'acquisizione dei dati passati in input attraverso l'interfaccia CGI, il corpo dello script si riduce ad invocare per prima la funzione “getCgiString”, memorizzandone l'output nella variabile stringa (riga 47) e successivamente richiamando per due volte la funzione “getCgiParam” per memorizzare nelle variabili nome e cognome i due dati presenti nella stringa ricevuta in input. Alle righe 56 e 57 i due dati vengono presentati in output nella pagina HTML composta dinamicamente.
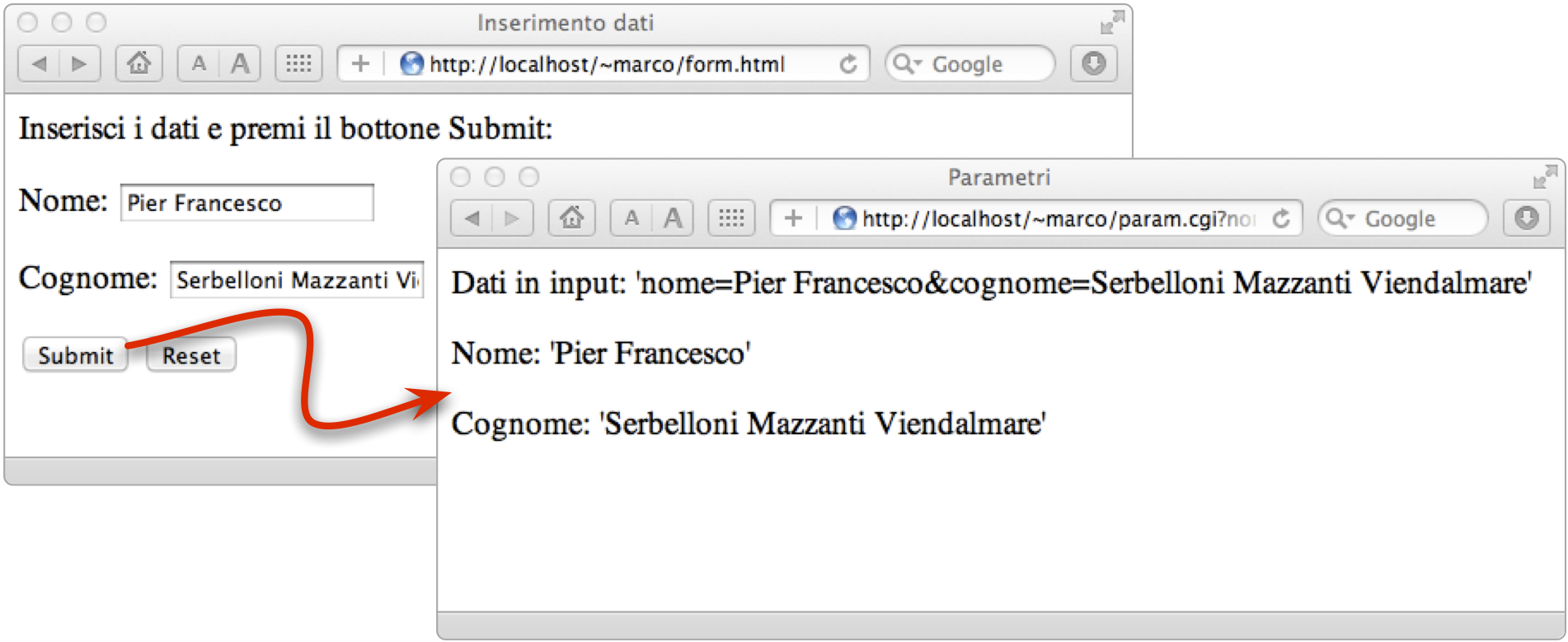
Esempio di output prodotto dallo script che acquisisce in input i dati inseriti nella form
In quest'ultimo esempio riscriveremo il programma per la gestione interattiva di una rubrica di indirizzi, presentato nella sezione “Rubrica degli indirizzi”, in modo tale da trasformarlo in un'applicazione web based.
Di fatto lo script deve operare in modo simile ad una modalità batch in cui, attraverso uno dei parametri, viene specificata la funzionalità che si intende eseguire. L'output naturalmente sarà prodotto in formato HTML in modo da poter essere visualizzato correttamente su un web browser; le operazioni di input dei dati saranno implementate con delle form HTML.
La struttura dell'applicazione web based è schematizzata in Figura. L'applicazione è basata su quattro file HTML ed uno script CGI. I file HTML sono dedicati uno al menù principale dell'applicazione e tre alle form di inserimento dei dati necessari ad effettuare le operazioni di inserimento di un record in archivio, di ricerca e visualizzazione dei record in archivio e di cancellazione di record dall'archivio. Lo script CGI è uno soltanto: riceve in input attraverso l'interfaccia CGI diversi parametri; tra questi il parametro “func” indica la funzionalità che si intende attivare e può quindi assumere i seguenti valori: “insert” per l'inserimento di un record in archivio, “select” per la ricerca e la visualizzazione e “delete” per la cancellazione di record.
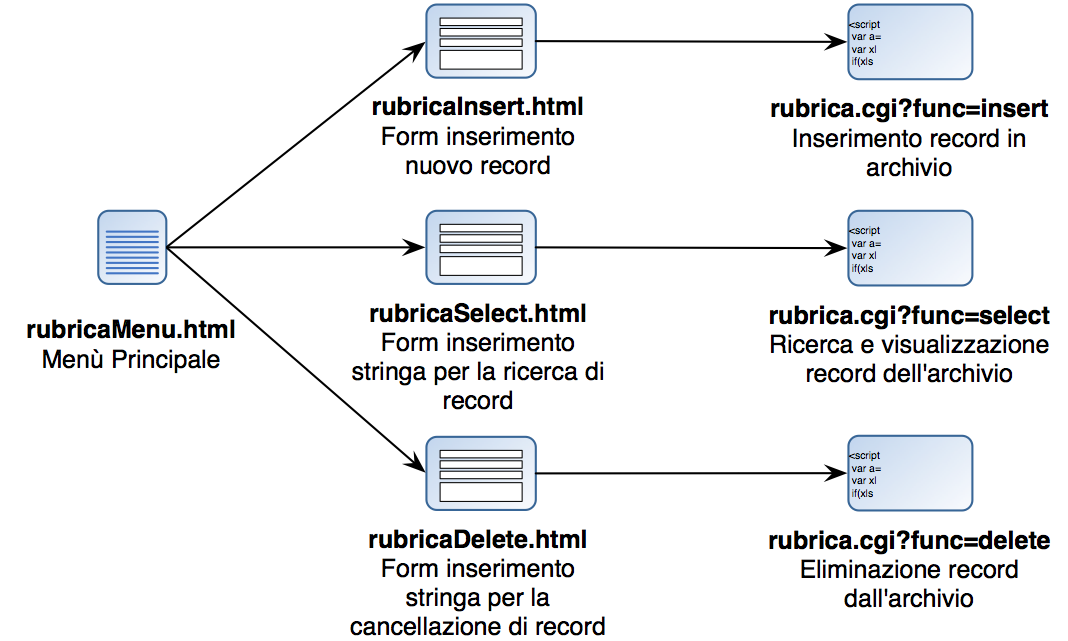
Schematizzazione delle relazioni tra le pagine HTML e le chiamate allo script CGI che implementa le diverse operazioni previste dall'applicazione web based: inserimento, selezione/visualizzazione e cancellazione dei record dall'archivio
Di seguito riportiamo il sorgente del primo file HTML, quello con il menù principale dell'applicazione. Il menù viene realizzato mediante una lista i cui elementi contengono i collegamenti ipertestuali alle pagine HTML con le form per l'inserimento dei dati da passare allo script CGI.
1 <html>
2 <head>
3 <title>Rubrica Indirizzi - Menù principale</title>
4 </head>
5 <body>
6 <h1>Rubrica Indirizzi</h1>
7 <p>Seleziona una delle funzioni disponibili:</p>
8 <ul>
9 <li><a href="rubricaInsert.html">Inserimento record</a>:
10 Inserimento di un nuovo record nell'archivio.</li>
11 <li><a href="rubricaSelect.html">Ricerca record</a>:
12 Visualizzazione record selezionati in base ad una stringa</li>
13 <li><a href="rubricaDelete.html">Cancellazione record</a>:
14 Cancellazione record selezionati in base ad una stringa</li>
15 </ul>
16 </body>
17 </html>
I file HTML con le form per l'inserimento dei dati sono piuttosto semplici. È importante osservare, però, che contengono tutte un campo di input denominato “func”, caratterizzato dall'attributo “hidden” che indica al browser che quel campo non deve essere visualizzato nella form. Il valore del campo “func” è diverso in ciascuna form, perché lo script CGI deve eseguire operazioni differenti a seconda della pagina da cui viene richiamato. Di seguito riportiamo il sorgente delle tre pagine, rispettivamente “rubricaInsert.html”, “rubricaSelect.html” e “rubricaDelete.html”.
1 <html>
2 <head>
3 <title>Rubrica Indirizzi - Inserimento record</title>
4 </head>
5 <body>
6 <h1>Rubrica Indirizzi</h1>
7 <p>Inserisci i dati nei campi e seleziona il bottone Submit
8 per salvarli in archivio:</p>
9 <form action="rubrica.cgi" method="POST">
10 <input type="hidden" name="func" value="insert">
11 <p>Nome: <input name="nome">
12 Cognome: <input name="cognome"></p>
13 <p>Telefono: <input name="telefono">
14 E-Mail: <input name="email"></p>
15 <p><input type="submit"> <input type="reset"></p>
16 </form>
17 </body>
18 </html>
1 <html>
2 <head>
3 <title>Rubrica Indirizzi - Ricerca record</title>
4 </head>
5 <body>
6 <h1>Rubrica Indirizzi</h1>
7 <p>Inserisci una stringa per selezionare i record da
8 visualizzare:</p>
9 <form action="rubrica.cgi" method="POST">
10 <input type="hidden" name="func" value="select">
11 <p>Criterio di selezione: <input name="stringa">
12 <input type="submit"> <input type="reset"></p>
13 </form>
14 </body>
15 </html>
1 <html>
2 <head>
3 <title>Rubrica Indirizzi - Cancellazione record</title>
4 </head>
5 <body>
6 <h1>Rubrica Indirizzi</h1>
7 <p>Inserisci una stringa per selezionare i record da
8 cancellare:</p>
9 <form action="rubrica.cgi" method="POST">
10 <input type="hidden" name="func" value="delete">
11 <p>Criterio di selezione: <input name="stringa">
12 <input type="submit"> <input type="reset"></p>
13 </form>
14 </body>
15 </html>
I quattro file HTML producono l'output riportato in Figura se richiamate con un web browser.

L'output prodotto dai file HTML dell'applicazione
Lo script CGI “rubrica.cgi” richiamato dalle tre form HTML, viene costruito modificando lo script “rubrica.sh” riportato nella sezione “Rubrica degli indirizzi”. Rispetto a quest'ultimo, lo script CGI non deve gestire il menù interattivo, ma deve solo invocare le diverse funzioni a seconda del valore del parametro “func” passato da ciascuna form HTML attraverso l'interfaccia CGI. Inoltre, naturalmente, viene modificato il modo di presentare l'output che, per l'applicazione web based, deve essere codificato in HTML per poter essere visualizzato correttamente mediante un web browser.
Per l'acquisizione dei dati in input attraverso l'interfaccia CGI, vengono utilizzate le funzioni “getCgiString” e “getCgiParam” già descritte nelle pagine precedenti. Di seguito riportiamo il sorgente completo dello script.
1 #!/bin/bash
2 #
3 # rubrica.cgi
4 # Rubrica telefonica web based.
5 #
6 RUBRICA="./rubrica.data"
7 #
8 # Funzione: getCgiString
9 # Acquisisce i parametri passati allo script attraverso l'interfaccia
10 # CGI e restituisce in output la stringa in formato URL-encoded
11 #
12 function getCgiString {
13 local stringa
14 if [ "$REQUEST_METHOD" == "GET" ]; then
15 stringa=$QUERY_STRING
16 else
17 read stringa
18 fi
19 stringa=$(echo $stringa | sed "s/%40/@/g")
20 stringa=$(echo $stringa | sed "s/\+/ /g")
21 echo "$stringa"
22 }
23 #
24 # Funzione: getCgiParam
25 # Estrae dalla stringa dei parametri quello il cui nome corrisponde
26 # con l'argomento della funzione; restituisce in output il valore
27 # del parametro
28 #
29 function getCgiParam {
30 local nome stringa a oldIFS cgiValue
31 nome=$1
32 stringa=$2
33 oldIFS=$IFS
34 IFS="&"
35 for parametro in $stringa; do
36 IFS="="
37 a=($parametro)
38 if [ "${a[0]}" == "$nome" ]; then
39 cgiValue=${a[1]}
40 break
41 fi
42 IFS="&"
43 done
44 IFS=$oldIFS
45 echo "$cgiValue"
46 }
47 #
48 # Funzione: recordInsert
49 # Riceve come argomento nome, cognome, telefono e e-mail
50 # e li inserisce in un nuovo record della rubrica
51 #
52 function recordInsert {
53 local nome=$1
54 local cognome=$2
55 local telefono=$3
56 local email=$4
57 echo "$nome|$cognome|$telefono|$email" >> $RUBRICA
58 echo "<p>Inserito record n. $(wc -l $RUBRICA | cut -c 1-8)</p>"
59 }
60 #
61 # Funzione: patternDelete
62 # Riceve una stringa ed elimina dalla rubrica tutti i record
63 # che contengono esattamente quella stringa
64 #
65 function patternDelete {
66 local f=$1
67 if [ $f ]; then
68 local n=$(grep "$f" $RUBRICA|wc -l)
69 grep -v "$f" $RUBRICA > $RUBRICA.new
70 mv $RUBRICA $RUBRICA.old
71 mv $RUBRICA.new $RUBRICA
72 echo "<p>Filtro: '$f' - Record eliminati: $n</p>"
73 else
74 echo "<p>ERRORE: non e' stato specificato nessun filtro</p>"
75 exit 1
76 fi
77 }
78 #
79 # Funzione: patternSelect
80 # Riceve una stringa e visualizza in output i record che contengono
81 # la stringa (selezione "case insensitive")
82 #
83 function patternSelect {
84 local record campo
85 local f="$1"
86 echo "<p>Filtro: '$f' - "
87 echo "Record selezionati: $(grep -i "$f" $RUBRICA | wc -l)</p>"
88 echo "<table border=\"1\"><tr><th>Nome</th><th>Cognome</th>"
89 echo "<th>Telefono</th><th>E-mail</th></tr>"
90 IFS=$'\n'
91 for record in $(grep -i "$f" $RUBRICA | sort -t \| -k 2)
92 do
93 echo -n "<tr>"
94 IFS='|'
95 for campo in $record
96 do
97 echo -n "<td>$campo</td>"
98 done
99 echo "</tr>"
100 done
101 echo "</table>"
102 unset IFS
103 }
104 #
105 # Procedura principale
106 #
107 stringa=$(getCgiString)
108 opt=$(getCgiParam func "$stringa")
109 echo "Content-Type: text/html"
110 echo
111 echo "<html><head><title>Rubrica Indirizzi - $opt</title></head>"
112 echo "<body><h1>Rubrica Indirizzi - $opt</h1>"
113 # Viene valutato il valore del parametro "func" che definisce
114 # l'operazione che deve essere eseguita dallo script
115 case $opt in
116 insert)
117 nome=$(getCgiParam nome "$stringa")
118 cognome=$(getCgiParam cognome "$stringa")
119 telefono=$(getCgiParam telefono "$stringa")
120 email=$(getCgiParam email "$stringa")
121 recordInsert "$nome" "$cognome" "$telefono" "$email";;
122 delete)
123 filtro=$(getCgiParam stringa "$stringa")
124 patternDelete "$filtro";;
125 select)
126 filtro=$(getCgiParam stringa "$stringa")
127 patternSelect "$filtro";;
128 esac
129 echo "<p><a href=\"rubricaMenu.html\">Torna al menù</a></p>"
130 echo "</body></html>"
Lo script CGI presenta alcune piccole varianti rispetto allo shell script interattivo. Innanzi tutto abbiamo modificato il path del file di archivio: ora si trova nella stessa directory dello script CGI (ad esempio in “/home/marco/public_html”) perché lo script non viene più eseguito con la nostra utenza personale, ma da un'utenza di sistema con cui opera il servizio HTTP server. Per questo lo script non è più in grado di risolvere il path “~/” come la nostra home directory. Inoltre l'utente che esegue il servizio HTTP server non è autorizzato a scrivere nella nostra home directory; per cui è opportuno spostare il file-archivio nella directory che ospita gli altri file della web application. Questa directory deve essere abilitata in scrittura in modo tale che anche l'utente che esegue il server HTTP possa modificare il file-archivio mediante l'esecuzione dello script “rubrica.cgi”. Il file-archivio è stato rinominato “rubrica.data” (riga 6).
Una modifica è stata apportata anche alla funzione “getCgiString”, introducendo l'istruzione a riga 19 che, utilizzando il comando “sed” esegue un'ulteriore decodifica della stringa con i dati in formato URL-encoded, traducendo la stringa “%40” nel carattere “@” che è presente negli indirizzi di posta elettronica gestiti dalla rubrica.
Il corpo principale dello script è costituito dalle istruzioni alle righe 107--130: dopo aver acquisito la stringa dei dati in input (riga 107), si estrae il valore del parametro “func” che viene memorizzato nella variabile opt (riga 108). Con un'istruzione “case” viene quindi valutato il valore contenuto in opt e di conseguenza vengono estratti i dati necessari dalla stringa URL-encoded e vengono invocate le funzioni che implementano le tre operazioni di inserimento, cancellazione e ricerca di record nell'archivio.
Concludiamo riportando un esempio di funzionamento del programma in Figura: vengono visualizzati tutti i record presenti in archivio contenenti la stringa “marco”.
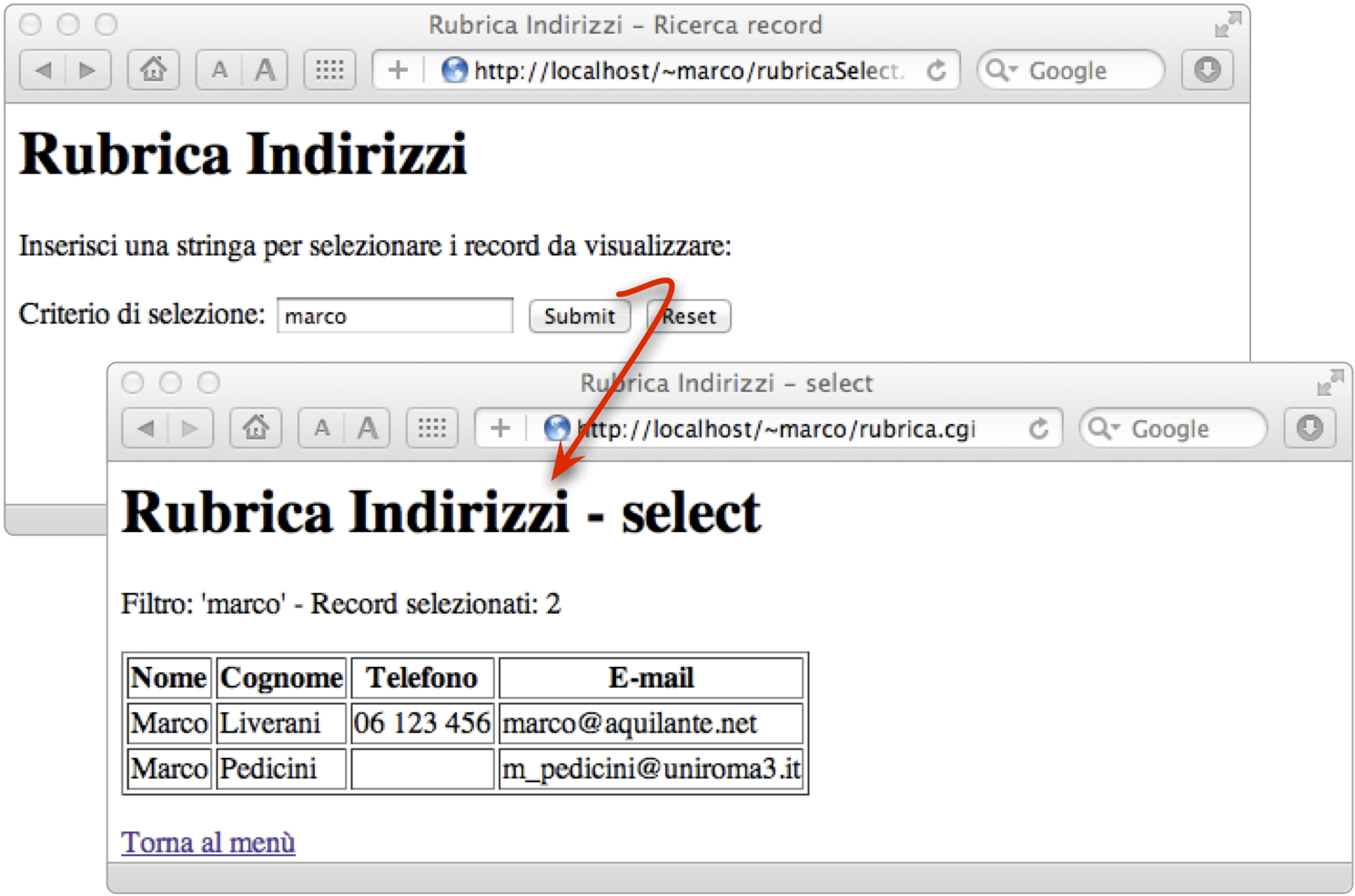
Due schermate dell'applicazione rubrica web based
Comandi interni, esterni e composti
Variabili, varibili d'ambiente e variabili speciali
Sintesi dei comandi principali
